

Liquid AI has released LFM2-Audio-1.5B, a compact audio–language foundation model that both understands and generates speech and text through a single end-to-end stack. It positions itself for low-latency, real-time assistants on resource-constrained devices, extending the LFM2 family into audio while retaining a small footprint.
But what’s actually new? a unified backbone with disentangled audio I/O
LFM2-Audio extends the 1.2B-parameter LFM2 language backbone to treat audio and text as first-class sequence tokens. Crucially, the model disentangles audio representations: inputs are continuous embeddings projected directly from raw waveform chunks (~80 ms), while outputs are discrete audio codes. This avoids discretization artifacts on the input path while keeping training and generation autoregressive for both modalities on the output path.
On the implementation side, the released checkpoint uses:
- Backbone: LFM2 (hybrid conv + attention), 1.2B params (LM only)
- Audio encoder: FastConformer (~115M, canary-180m-flash)
- Audio decoder: RQ-Transformer predicting discrete Mimi codec tokens (8 codebooks)
- Context: 32,768 tokens; vocab: 65,536 (text) / 2049×8 (audio)
- Precision: bfloat16; license: LFM Open License v1.0; languages: English
Two generation modes for real-time agents
- Interleaved generation for live, speech-to-speech chat where the model alternates text and audio tokens to minimize perceived latency.
- Sequential generation for ASR/TTS (switching modalities turn-by-turn).
Liquid AI provides a Python package (liquid-audio) and a Gradio demo to reproduce these behaviors.
Latency: <100 ms to first audio
Liquid AI team reports end-to-end latency below 100 ms from a 4-second audio query to the first audible response—a proxy for perceived responsiveness in interactive use—stating it is faster than models smaller than 1.5B parameters under their setup.
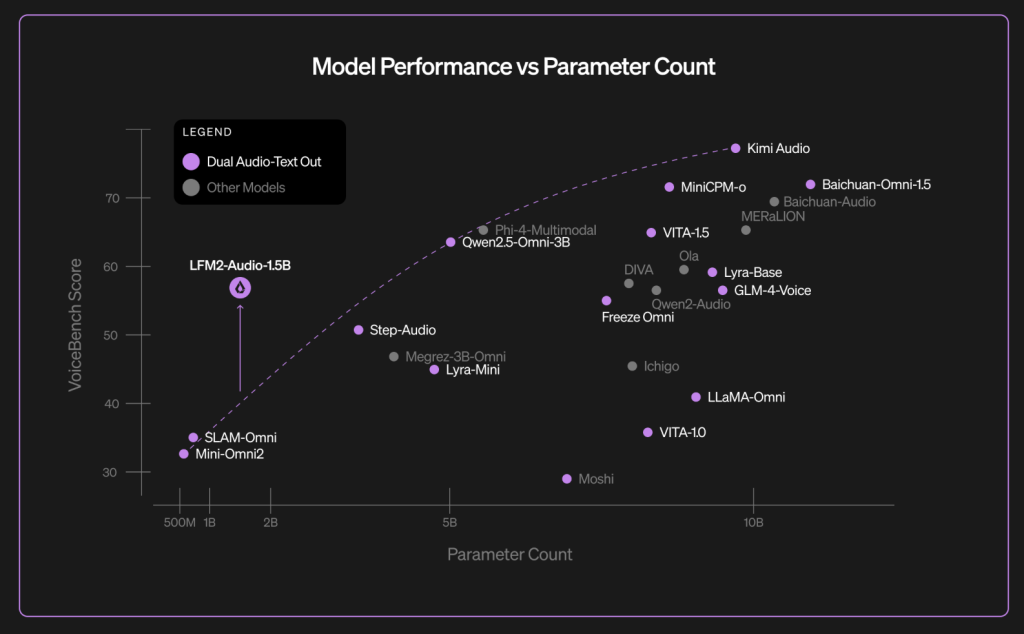
Benchmarks: VoiceBench and ASR results
On VoiceBench—a suite of nine audio-assistant evaluations—Liquid reports an overall score of 56.78 for LFM2-Audio-1.5B, with per-task numbers disclosed in the blog’s chart (e.g., AlpacaEval 3.71, CommonEval 3.49, WildVoice 3.17). The Liquid AI team contrasts this result with larger models like Qwen2.5-Omni-3B and Moshi-7B in the same table. (VoiceBench is an external benchmark introduced in late 2024 for LLM-based voice assistants)
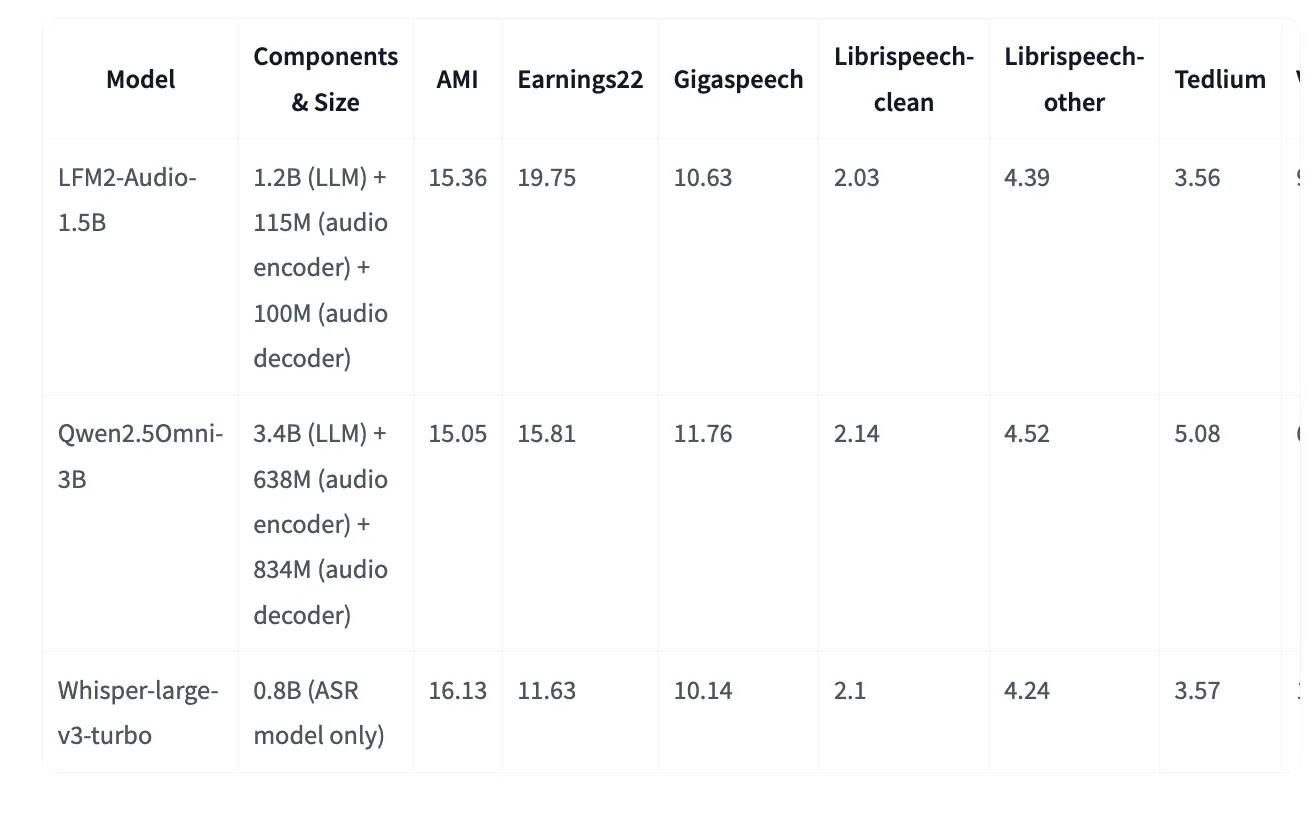
The model card on Hugging Face provides an additional VoiceBench table (with closely related—but not identical—per-task values) and includes classic ASR WERs where LFM2-Audio matches or improves on Whisper-large-v3-turbo for some datasets despite being a generalist speech–text model. For example (lower is better): AMI 15.36 vs. 16.13 (Whisper-large-v3-turbo), LibriSpeech-clean 2.03 vs. 2.10.
Alright, but why does it really matter in voice AI trends?
Most “omni” stacks couple ASR → LLM → TTS, which adds latency and brittle interfaces. LFM2-Audio’s single-backbone design with continuous input embeddings and discrete output codes reduces glue logic and allows interleaved decoding for early audio emission. For developers, this translates to simpler pipelines and faster perceived response times, while still supporting ASR, TTS, classification, and conversational agents from one model. Liquid AI provides code, demo entry points, and distribution via Hugging Face.
Check out the GitHub Page, Hugging Face Model Card and Technical details. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.